LLMBlitz.io
See inside
large language models.
Browser-based tools for engineers, researchers, and learners.

LLMBlitz.io
Generate empirically
optimized prompts.
Prompt Designer creates ranked & tested system prompts for optimal LLM generation in your app.
Try Prompt Designer →
LLMBlitz.io
Predict LLM token cost
for all major LLMs.
Paste any text and instantly compare token counts and API costs across models.
Try Tokenizer+ →What is LLMBlitz.io?
LLMBlitz.io is a largely free platform offering tools to explore LLM internals, optimize performance, and reduce costs.
LLM Tools You Can Use
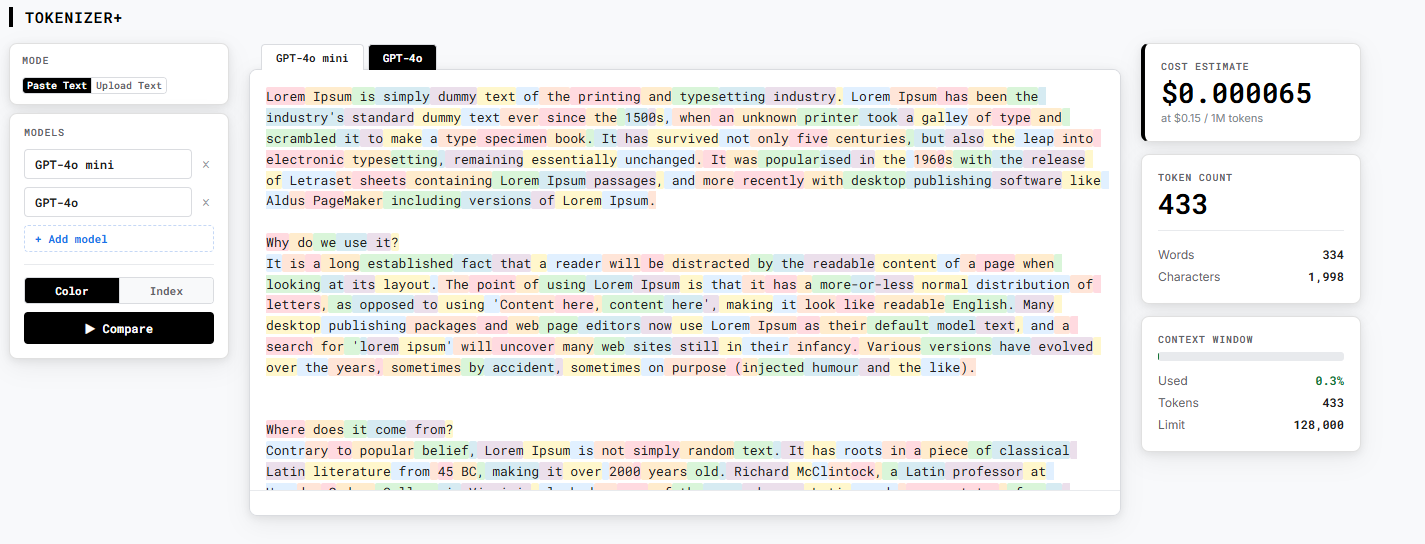
Problem this tool solves: You don't know how many tokens your text uses or what it will cost until after you've already made an API call — and most tools only show you one model at a time.
Paste any text and instantly see how any major LLM breaks it into tokens — color-coded, with token IDs, counts, and live cost estimates. Unlike provider playgrounds that only show one model at a time, Tokenizer+ compares up to three models side by side so you can see exactly how GPT-4o, Claude, and Llama tokenize the same input differently and what that means for your cost and context window. Switch to Batch Estimate mode to upload a full dataset and forecast total API spend — including the 50% discount from the OpenAI Batch API — before committing to a run.
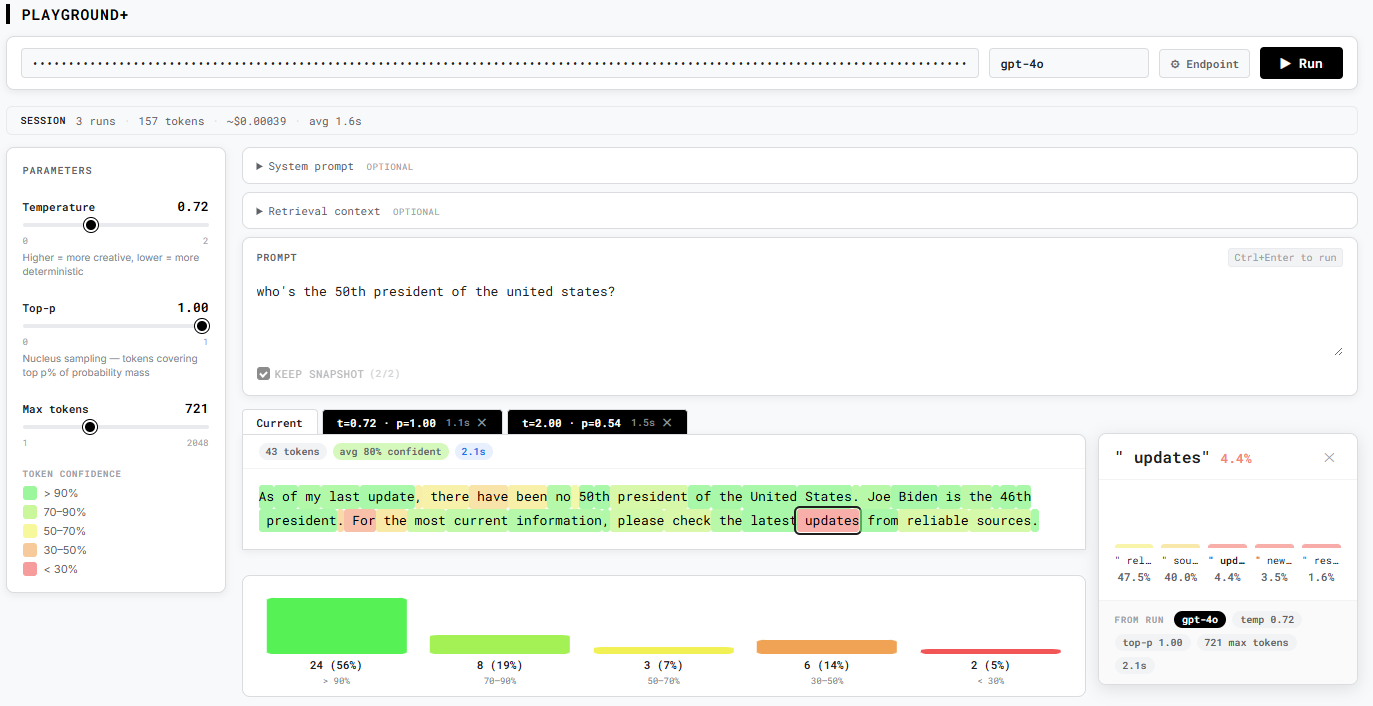
Problem this tool solves: LLM playgrounds show you what the model said — but not why it said it, how confident it was, where exactly it went wrong, or how one run compares to another.
Most playgrounds show you what the model said. Playground+ shows you why. Every output token is color-coded by confidence — hover to see what the model almost chose instead, click to pin a full probability bar chart for that position. Built-in failure detection automatically flags hallucination risk, refusals, and formatting misses from the token distribution itself, without reading the output line by line. Works with any OpenAI-compatible endpoint, including local models via Ollama or LM Studio — no lock-in to a single provider.
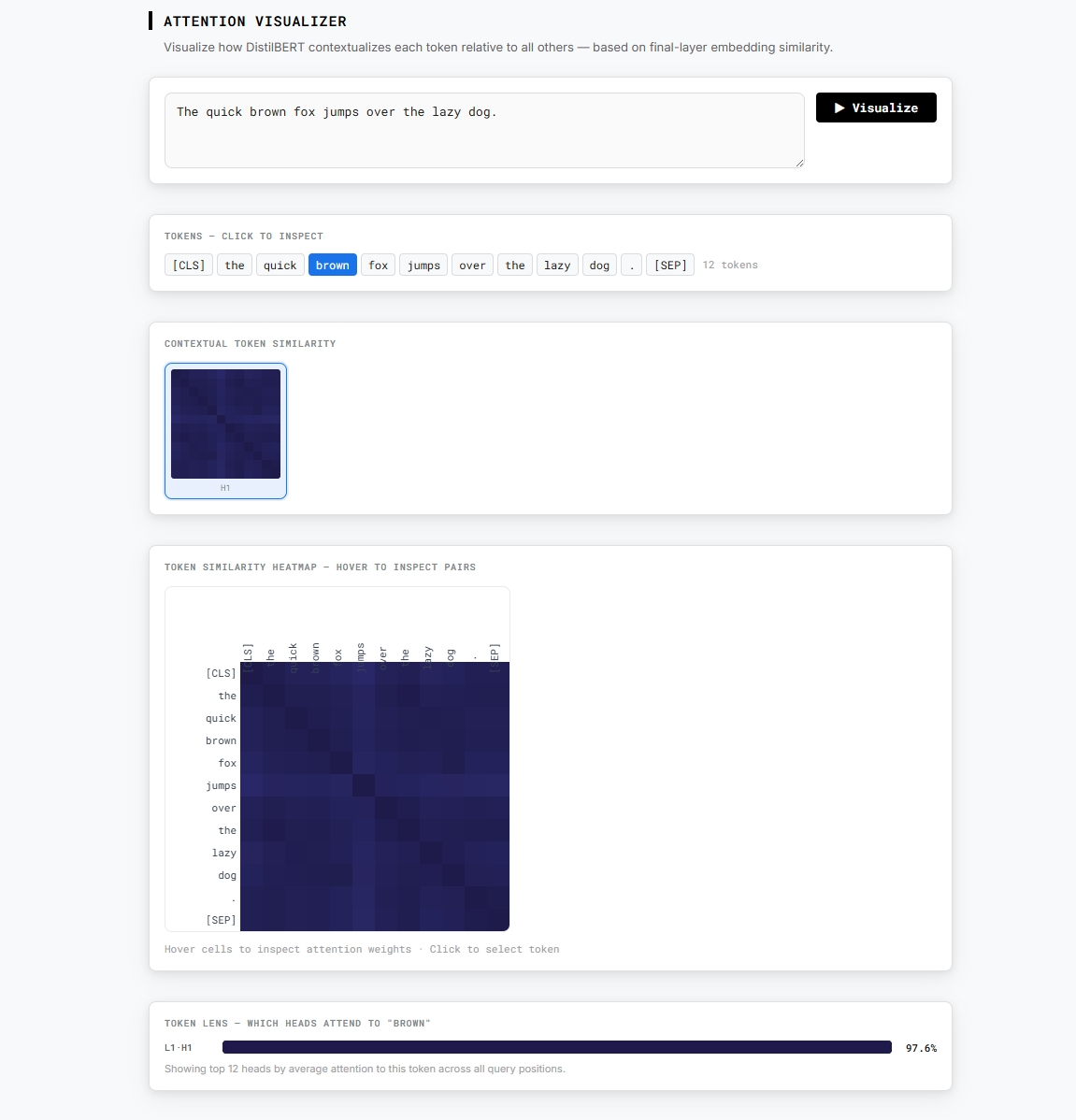
Problem this tool solves: Transformer explanations are usually static diagrams that can't show how a model actually represents your specific text in embedding space.
Every transformer explainer uses static diagrams. Embedding Explorer runs a real model — DistilBERT, fully in your browser with no API key — and shows you a live contextual similarity heatmap of token embeddings. See exactly how the model relates "bank" to "river" versus "deposit", how negation links "not" to "good", and how pronouns resolve to their referents. Click any token to activate the Token Lens and inspect which heads focus most on that position. The theory, made interactive.
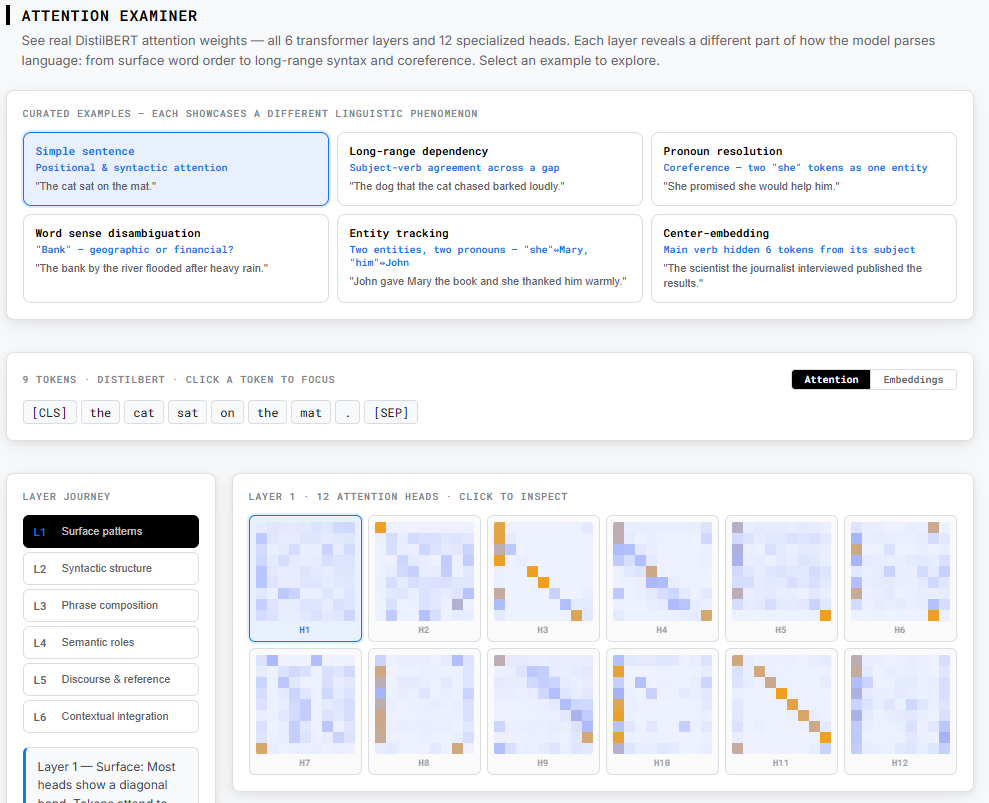
Problem this tool solves: Transformer papers describe attention and embeddings in the abstract — but you can't actually see how a real model builds up meaning layer by layer for a specific sentence.
Attention Examiner shows real numbers from a real model — DistilBERT — running on real sentences. No simplified diagrams. Switch between the Attention view (which tokens did each token look at, per layer and per head) and the Embeddings view (how similar are each token's representations after each layer). Watch "bank" drift toward "river" across layers as word-sense disambiguation resolves. See "dog" and "barked" form a long-range subject-verb link in layer 4 despite a full embedded clause between them. Track two instances of "she" converge in representation as coreference resolves. All data is pre-computed from real model weights — instant load, zero download.
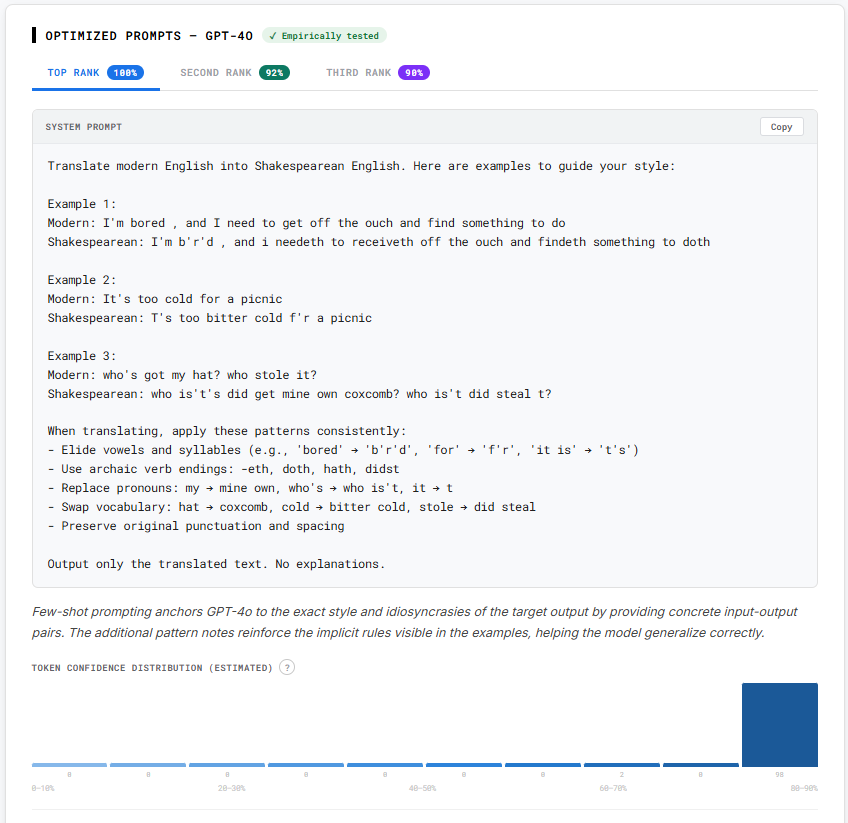
Problem this tool solves: Crafting predictable system prompts can be jarring. This tool takes out the guess work and designs empirically tested prompts.
Prompt Designer turns your examples into ranked system prompts. Paste or upload input/output pairs and a task description, then get multiple prompt candidates with rationales and confidence histograms. Optionally connect your own API key to measure prompts empirically, and send the winner straight into Playground+ to test against real workloads.